Screep 私服指标看板搭建&实施
背景
由于最近TS在AI圈再次伟大,秉承着深入学习TypeScript的想法,重新下载回了Screep,准备再次体验下这款使用JS脚本驱动的游戏
但是Screep在公服上竞争激烈,国人很容易被针对,遂部署了对应的私服进行娱乐,并且拉上了自己的小伙伴
既然拥有了私服,那么就拥有了原始的数据,且在Screep上步入更后期的优化,需要有相对应的数据支撑来指导,以及联动异常告警
于是便有了搭建一份指标看板的想法

目标
对于核心Screep中的资源、人力、矿物等相关数据进行统计,查看趋势
当Screep中的资源、人力、矿物出现异常时,联动告警
使用TypeScript写一个Node.js服务对MongoDB的数据进行采集,来提升对于TypeScript的熟练度
对于服务链路,涉及到的中间件具有可复用性,能后续把其他监控、告警、看板接入进来
拆解
数据采集器,用于采集数据
时序数据存储库,用于存储采集器每秒从MongoDB采集出的数据
通过看板工具,看板平台,将时序数据直观的展现
一个支持时序数据为底的告警平台
设计
整体设计
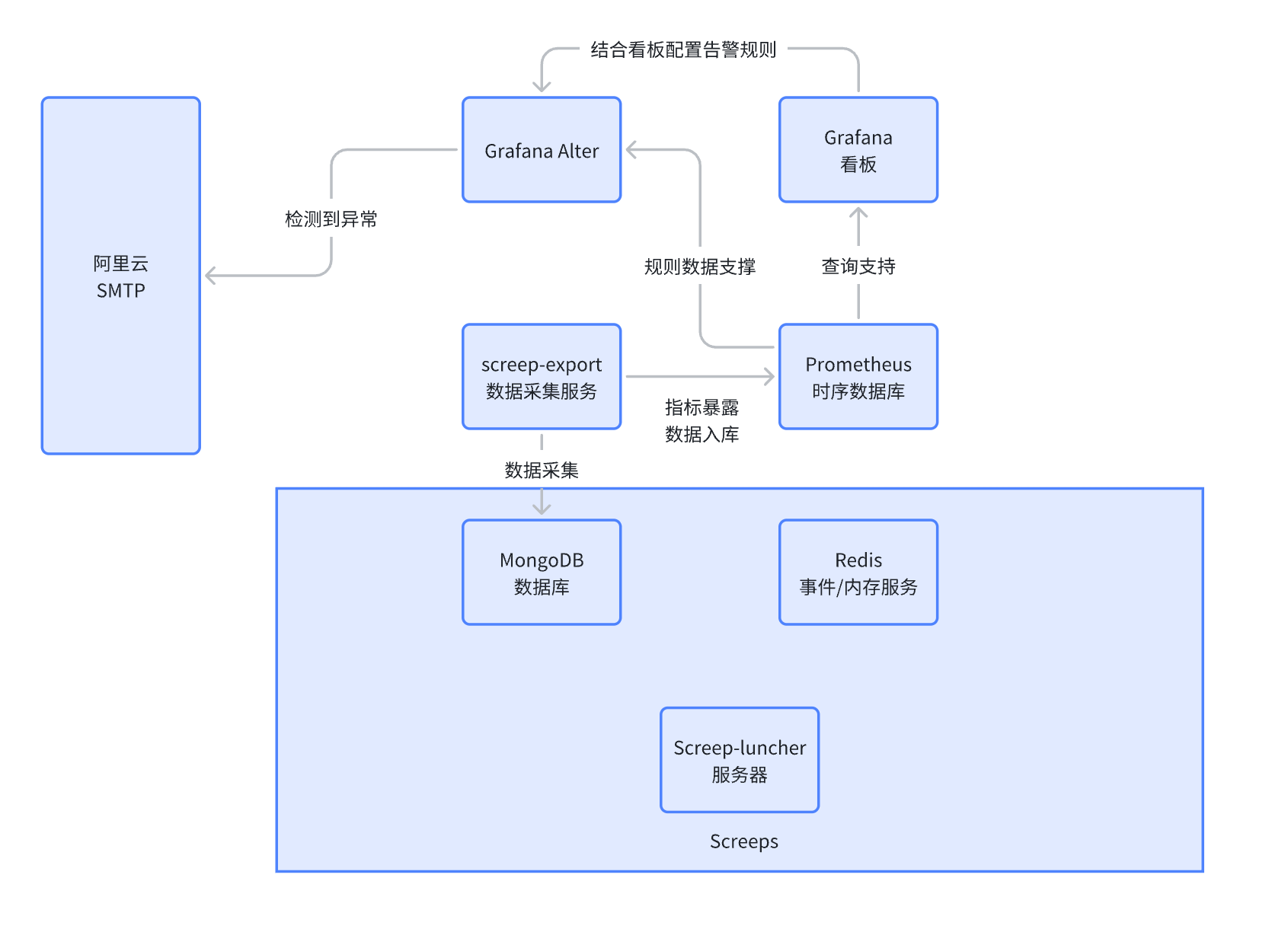
Q: 为什么采用Grafana和Prometheus?能带来什么更好的优势?
A: 因为Prometheus是一个很成熟的时序数据库,可以在多个地方被复用,且对于已有的k3s集群,他可以直接接管k3s的集群监控,而Grafana则是和Prometheus共生的一个监控看板,有着极高的支持度,且允许配置告警到SMTP上,组成完美链路供后续复用
指标设计
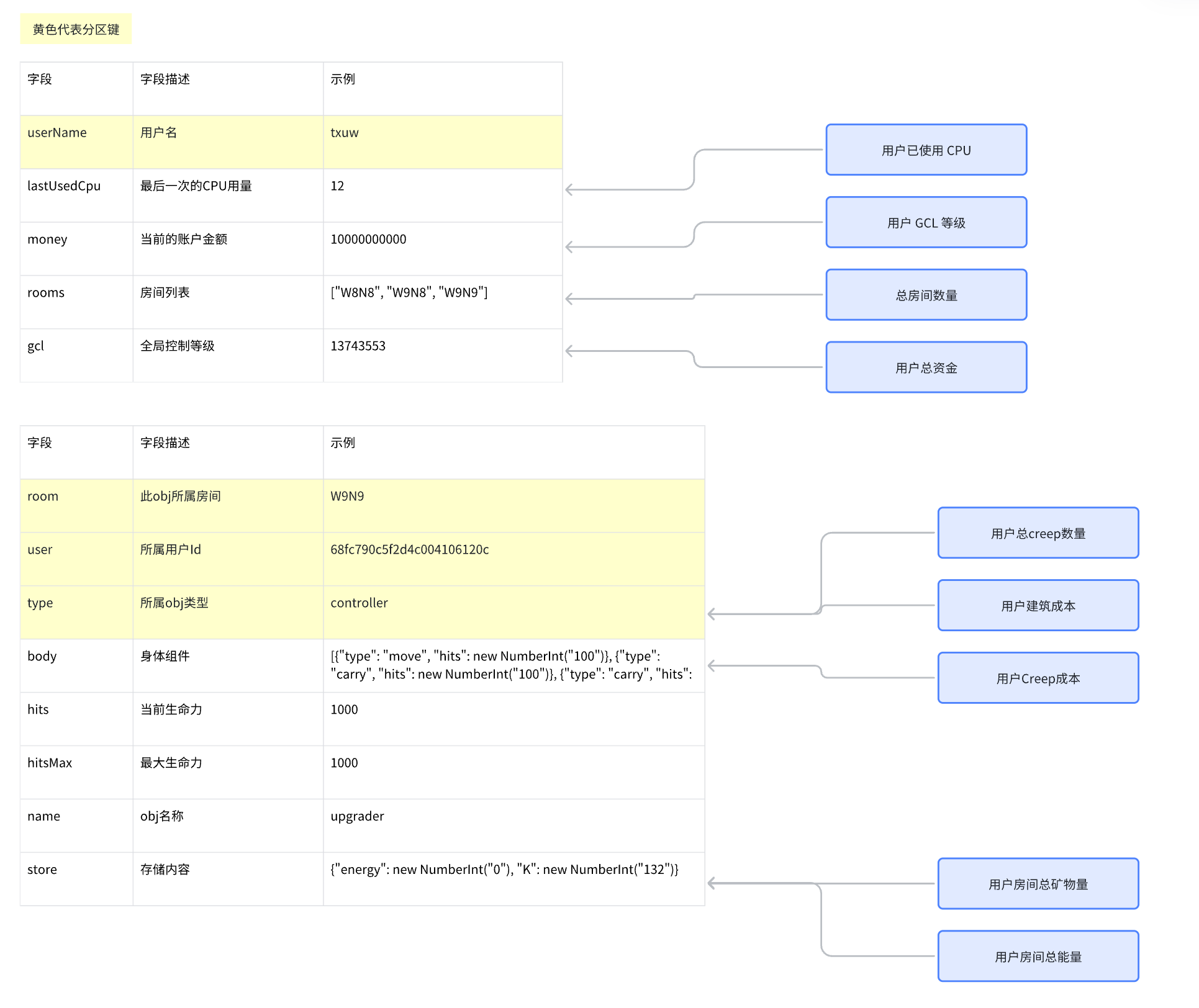
数据库基础数据/字段
仅展示Screep私服中所用到的MongoDB的字段
MongoDB数据
User表
RoomObj表
数据指标设计
整体数据指标氛围用户相关、房间相关
对于用户相关有:用户已使用CPU、用户GCL等级、总房间数量、用户总资金
对于房间相关有:用户总Creep数,用户建筑成本,用户Creep成本,用户房间总矿物量,用户房间总能量
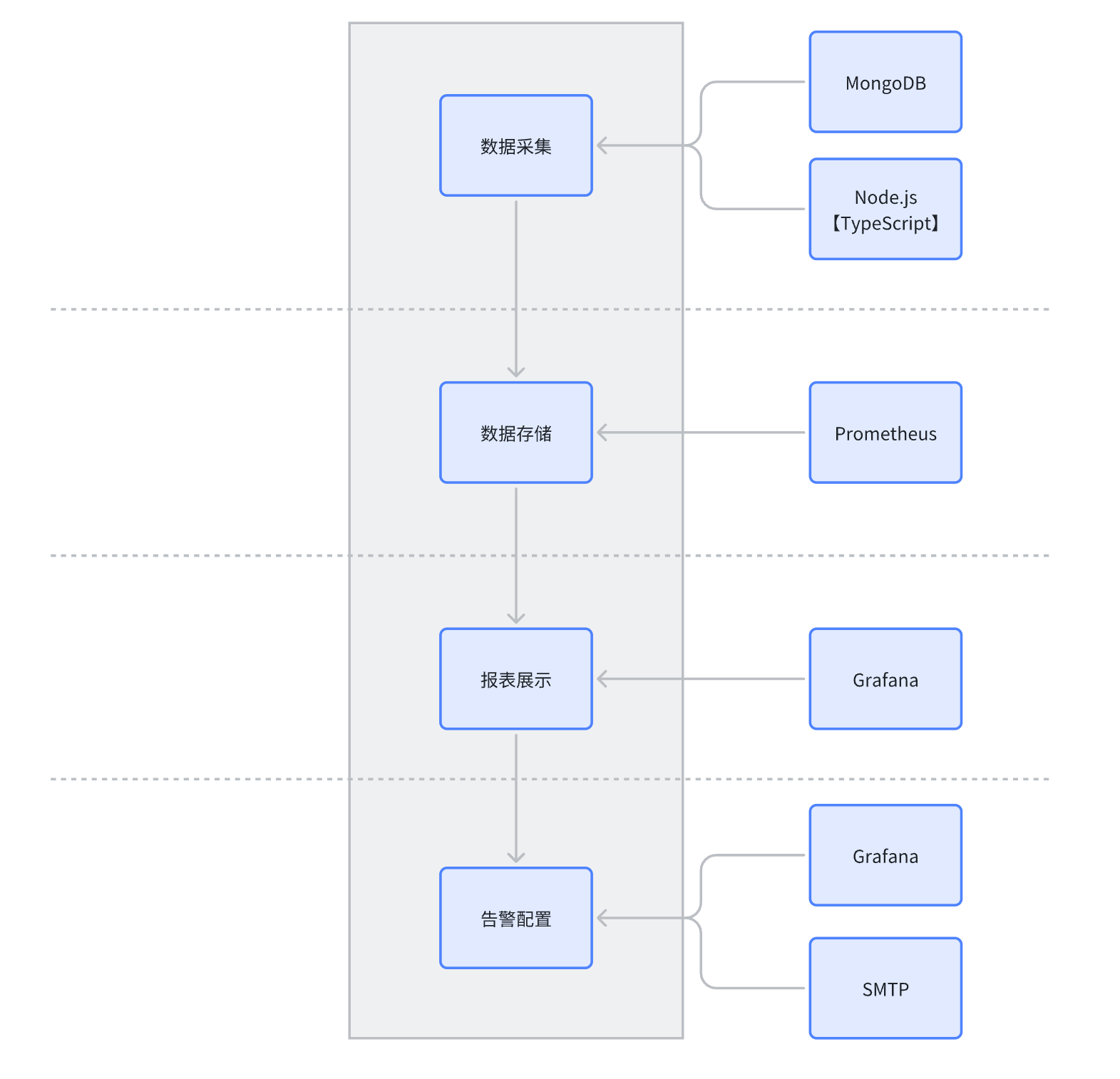
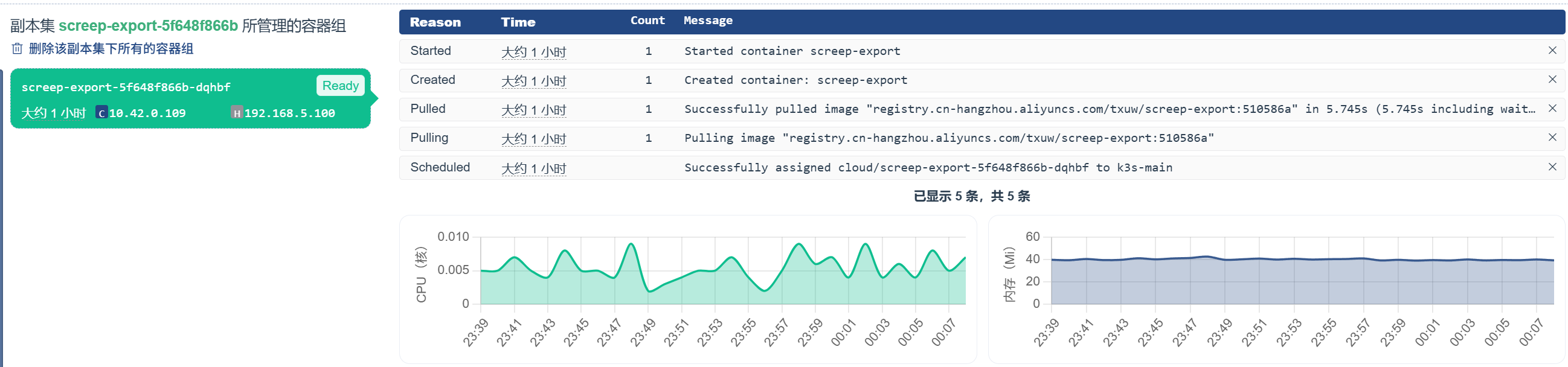
实施
实施Map图如下,由数据采集模块、数据存储模块、报表展示模块、告警配置模块组成
Screep-export数据采集暴露
对于Screep-export,为自实现项目,链接如下
其主要采用Node.js实现的一个轻量级项目,采用从 MongoDB 数据库中提取 Screep 游戏数据,并将其转换为 Prometheus 监控系统可识别的指标格式,具体相关介绍已在ReadMe中讲解
选型思考
为什么对于整体项目采用Node.js和最轻量级的Express进行项目实现?
因为整体数据采集器应该是很轻量,高效的,对于轻量级、强生态的语言和Node.js比的只有Python,但是我更想学习TS,所以采用Node.js
而Express的选用更是切合轻量的概念,因为本身不是很需要很重的框架,只是做一层数据的Convert,怎么轻怎么来,而且在实现后也果真也非常轻,非常高效,内存稳定CPU消耗低
而且更底层的实现更利于我学习TS的核心思想,而不是在于对框架的学习上
框架学习
env的引入
通过dotenv的使用,会处理项目根目录下的一个.env文件,读入以其中的键值对后,注册到全局变量process.env上,使得变量能被全局使用
相较于Java的Springboot等框架的yaml的依赖注入,.env会更为轻量级
MongoDB框架的配置
Node.js的生态原生支持MongoDB,而且受JS/TS的特性,像MongoDB这种文档型数据库,其中的不定类型字段,更适配于TS,而且基于原先Java的习惯,和常规后端习惯,进行了连接池的配置相当好用
/**
* MongoDB 客户端连接选项
*/
export const clientOptions: MongoClientOptions = {
maxPoolSize: 50, // 最大连接数(根据你的并发需求调整)
minPoolSize: 5, // 最小保持的连接数
maxIdleTimeMS: 30000, // 空闲连接30秒后关闭
connectTimeoutMS: 10000, // 10秒连接超时
socketTimeoutMS: 45000, // 45秒操作超时
serverSelectionTimeoutMS: 5000, // 5秒服务器选择超时
retryWrites: true,
retryReads: true,
};Prometheus框架的使用
定义指标 (Define Metrics):创建
Counter、Gauge、Histogram或Summary的实例来代表你想要监控的系统状态。注册指标 (Register Metrics):将这些指标实例注册到一个
Registry中。更新指标 (Update Metrics):在你的应用逻辑中,根据事件(如收到请求、任务完成等)更新这些指标的值。
暴露端点 (Expose Endpoint):创建一个 HTTP 端点(通常是
/metrics),当 Prometheus 服务器访问此端点时,返回Registry中所有指标的当前状态,格式为 Prometheus 的文本格式。
对于Registry,是所有指标的入口,负责收集所注册的指标,并调用配置好的业务逻辑,转化为Prometheus的指标格式
prom-client提供了一个全局默认的 Registry ,也可以自己指定防止冲突
而对于Gauge 来说,通常用于记录数值,供Prometheus采集,也是最常用的一个类型
// 定义
private readonly usersEnergyGauge: Gauge<string>;
this.usersEnergyGauge = new Gauge({
name: 'screep_users_energy',
help: 'Total number of active users energy',
labelNames: ['userName','room'],
registers: [this.registry],
});
// 使用
for (let energyCount of this.getEnergyCount(energyObjs)) {
this.usersEnergyGauge
.labels(energyCount.userName,energyCount.room)
.set(energyCount.totalEnergy)
}而其中的Label,会存储到Prometheus中,便于后续使用时,进行分组,聚合等操作,整体格式为
# HELP screep_users_energy Total number of active users energy
# TYPE screep_users_energy gauge
screep_users_energy{userName="txuw",room="W1N1"} 124379
screep_users_energy{userName="txuw",room="W2N1"} 276387
screep_users_energy{userName="txuw",room="W2N2"} 383366
screep_users_energy{userName="txuw",room="W5N3"} 1845
screep_users_energy{userName="obsidianlyg",room="W8N8"} 942916
screep_users_energy{userName="obsidianlyg",room="W9N8"} 799846
screep_users_energy{userName="obsidianlyg",room="W9N9"} 750360
screep_users_energy{userName="Dylan",room="W5N8"} 469791
screep_users_energy{userName="Dylan",room="W4N9"} 4544
screep_users_energy{userName="Dylan",room="W1N8"} 6954TS学习
从个人的学习角度,在其中领略到的几个TS特性
对于不定类型结构的字段判定
let mineralsObjs = roomObjs.filter(obj => {
if('store' in obj && obj.store && typeof obj.store === 'object'){
// 获取 store 对象的所有键,排除 energy,检查是否还有其他属性
return Object.keys(obj.store).some(key => key !== 'energy');
}
return false;
})在这段代码中,obj传递进来时是一个any类型,但是TypeScript可以通过'store' in obj 来判断obj是否具有 store这个属性
对比于Java的类反射,所需要涉及到的类序列的反向解析产生的性能代价和操作难度来说,还是方便了很多
此外获取整个类结构的字段,只需要Object.keys(obj.store)便可以获取一个不定类的字段string,相当方便
而对于TypeScript这类解释型语言,其产生的代价也很低,性能也很高
对于TypeScript中 for of语法
for (let structCost of this.getStructCostInfo(structObjs)) {
this.usersStructCostGauge
.labels(structCost.userName,structCost.room,structCost.structType)
.set(structCost.totalCost)
}其功能和Java中的迭代器类似,但是TypeScript中是通过Symbol.iterator方法即可通过语法糖调用
而Java是需要implements Iterable 并实现hasNext() 和 next() 两个独立方法后,会在编译时被转化为一个循环语句
变量定义之 const、let、var
这三个变量的定义涉及到变量的作用域,以及变量的赋值/声明
var 是一个旧的变量定义方式,他的作用域会被提升到全局function,不会只作用在当前for循环等,且可被重复赋值/声明 导致意外Bug
let 是ES6引入的新方式,是受限的作用域,只作用在{}代码块内部(例如 if, for, while 或者直接用 {} 包裹的代码块),无法被重复声明
const和let差不多,但是他无法被重复赋值/声明,且变量内存地址唯一,和Java中的常量一致
import和export的类加载逻辑
在TypeScript中每个文件都是一个Module,比Java的类的概念更高一层
每文件内部有自己的作用域。在一个文件中定义的变量、函数、类,默认情况下在其他文件中是不可见的。
模块可以选择性地通过 export 关键字,将其内部的成员(变量、函数、类、接口等)暴露给其他模块。
其他模块可以通过 import 关键字,来获取并使用这些被暴露的成员
Prometheus数据入库/存储与查询原理
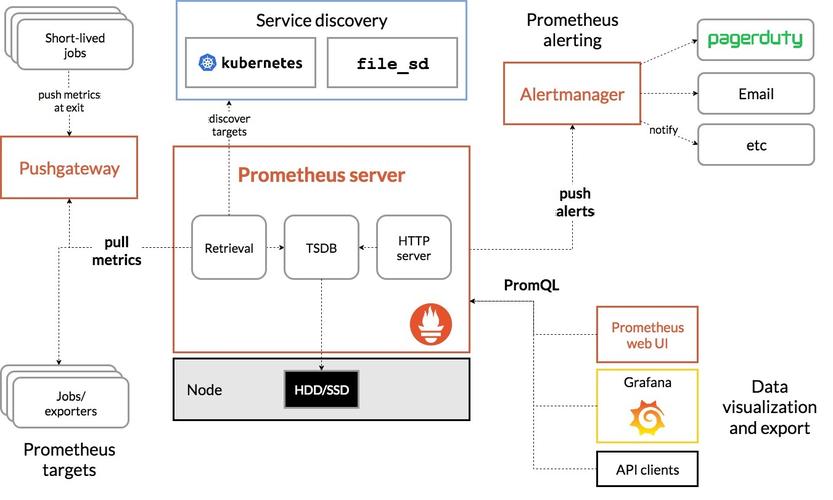
数据入库模式
Prometheus支持推、拉两种方式
对于可以自己暴露EndPoint的服务,Prometheus支持拉模式,通过访问服务EndPoint,来拉取数据
对于无法暴露但是可以向Prometheus发送数据的服务,可以使用推模式,就是将数据Push到Prometheus的GateWay上,进行入库
数据存储优势
内存数据结构
磁盘数据结构
数据查询原理
数据插入原理
数据查询原理
Grafana+Prometheus的集群部署
基于K3S和helm进行Grafana和Prometheus的集群安装
需要注意安装时如果存在其他的Prometheus的服务会产生冲突
# helm安装Prometheus的仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 更新仓库
helm repo update
# 安装Prometheus集群
helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring --values values.yaml注意其中的values,需要按个人所需调整
# Grafana 配置
grafana:
# 建议修改为你的密码
adminPassword: ""
# 使用 longhorn 进行数据持久化
persistence:
enabled: true
storageClassName: "longhorn" # 指定使用 longhorn【根据自身需要调整】
size: 10Gi # Grafana 的数据盘,
# 资源请求限制调到所需
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 1
memory: 2Gi
# 使用 NodePort 方便在开发环境访问
service:
type: NodePort
# 开启SMTP
envFromSecret: "grafana-smtp-credentials"
grafana.ini:
server:
root_url: https://grafana.txuw.top
smtp:
enabled: true
host: "smtpdm.aliyun.com:465"
user: ""
password: ${SMTP_PASSWORD}
from_address: ""
from_name: "Grafana"
skip_verify: false
starttls_policy: "NoStartTLS"
# Prometheus 配置
prometheus:
prometheusSpec:
# 配置数据保留时间
retention: 15d
# 配置最大存储磁盘量
retentionSize: "70GiB"
# 副本数设置为1,非高可用
replicas: 1
# 资源请求限制调到所需
resources:
requests:
cpu: 500m
memory: 2Gi
limits:
cpu: 2
memory: 4Gi
# Prometheus 数据持久化,使用 longhorn
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: "longhorn" # 指定使用 longhorn
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi # Prometheus 的数据盘
# Alertmanager 配置
alertmanager:
# 1. 开启 Alertmanager
enabled: true
# 为 Alertmanager 配置持久化和低资源
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: "longhorn"
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 1
memory: 1Gi
# 其他核心组件也调低资源
kube-state-metrics:
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
prometheus-node-exporter:
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi注意事项
当Prometheus的服务产生冲突时,会导致Prometheus主服务无法启动,反复重启
当配置资源量过小时,会导致Prometheus主服务无法启动,反复重启
Grafana看板绘制
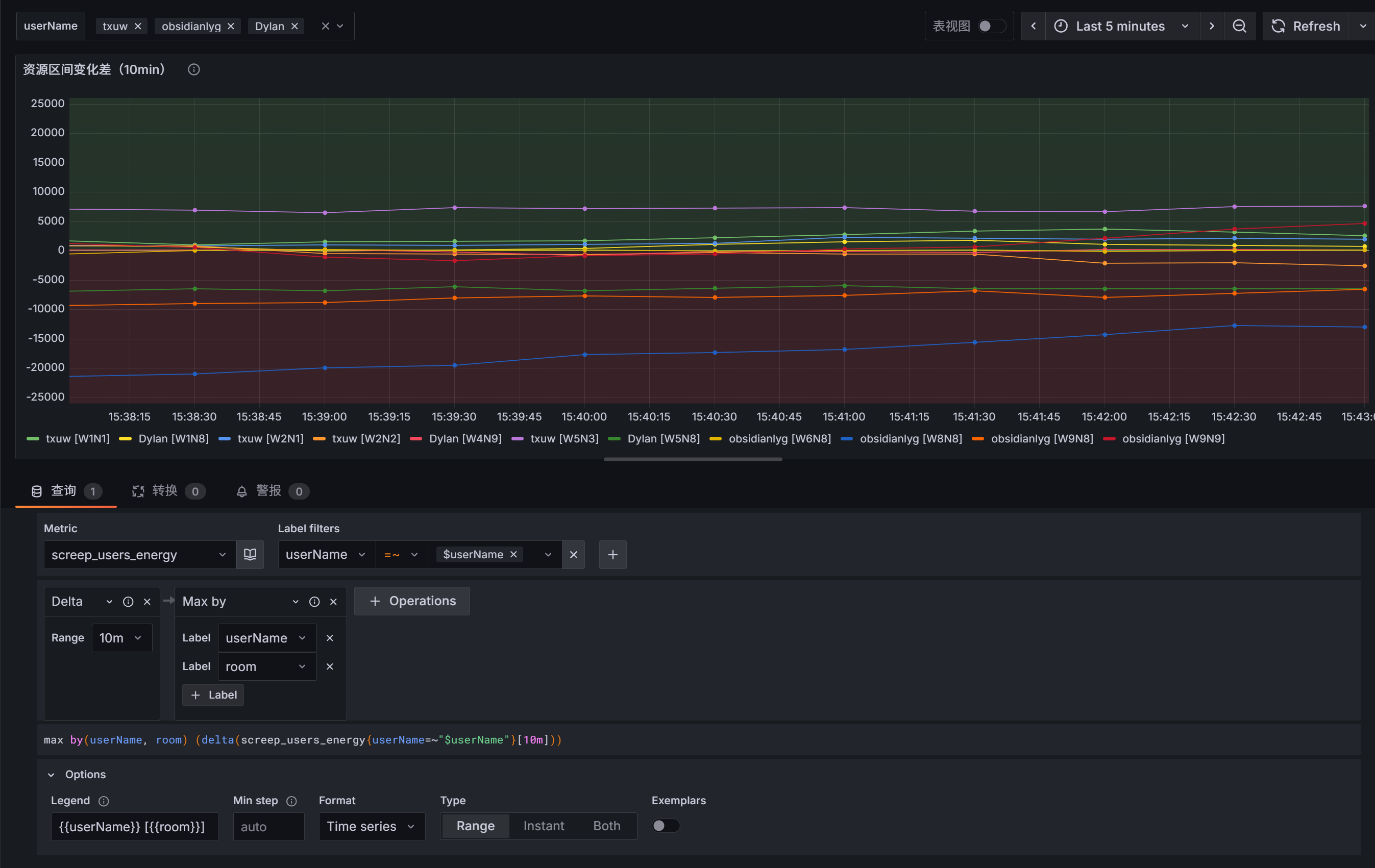
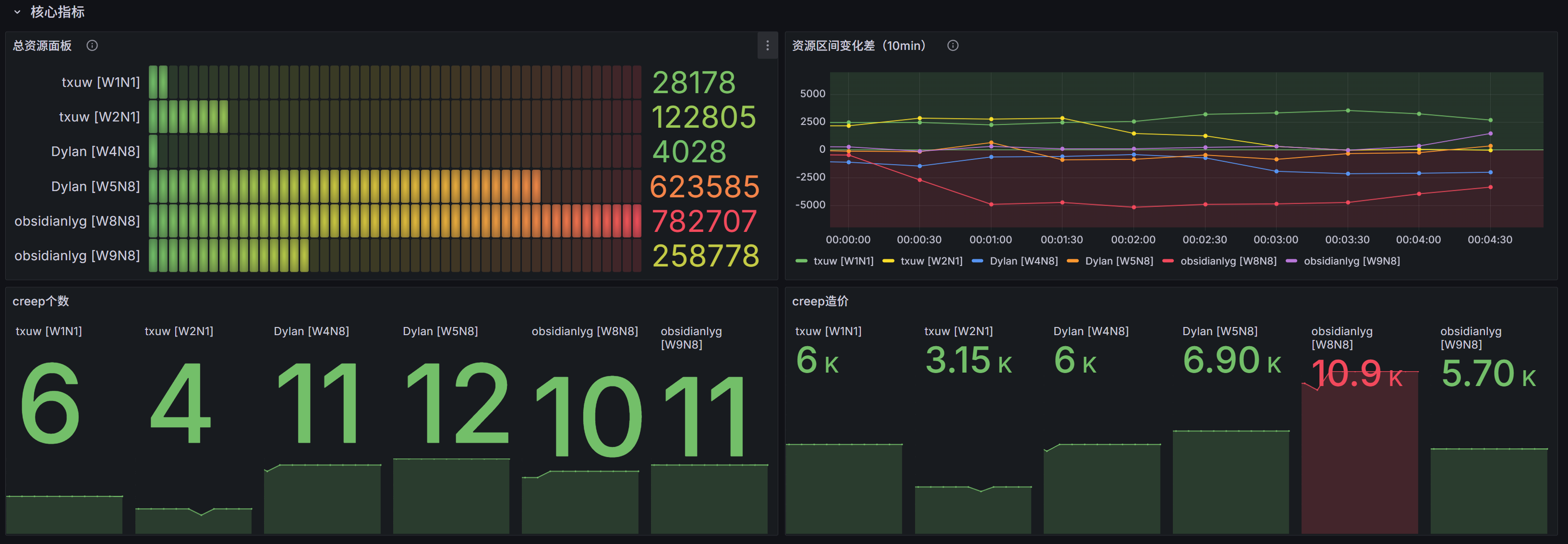
所示图中,即为使用了screep_users_energy 指标
通过Delta函数,判断10min内整体的资源变化率,而后按照userName,room分组即可得出每个用户的房间下的资源变化率
而后的Max by用于聚合screep-export服务在k3s环境中重发时,引发的pod变更导致id变化的问题
最后的options,则是用于让显示的指标显示 userName [room],便于查看
当长期处于0值以下时,就说明房间一直在负开支,需要优化房间的具体资源配比
具体screep_users_energy 的数值可以参考Screep-export项目中的代码实现
// 筛选出roomObjs中的energy Obj
let energyObjs = roomObjs.filter(obj => 'store' in obj && 'energy' in obj.store)
// 获取指标数据
getEnergyCount( energyObjs :any[]){
// 使用对象作为临时存储
const grouped: Record<string, {
room: string;
userName: string ;
totalEnergy: number;
}> = {};
for (let energyObj of energyObjs) {
const energy = energyObj.store?.energy as number || 0;
const username = energyObj.user?.toString() || '';
const roomName = energyObj.room || '';
const key = `${username}_${roomName}`;
if (!grouped[key]) {
grouped[key] = {
room: roomName,
userName: username,
totalEnergy: 0
};
}
grouped[key].totalEnergy += energy;
}
return Object.values(grouped)
}Grafana配置阿里云SMTP
开通SMTP
需要进入阿里云的邮件推送服务,开通邮件推送,其中有固定的免费额度,目前看起来是用不完的
域名配置
而后需要进行域名配置,具体教程如下
完成后参考下方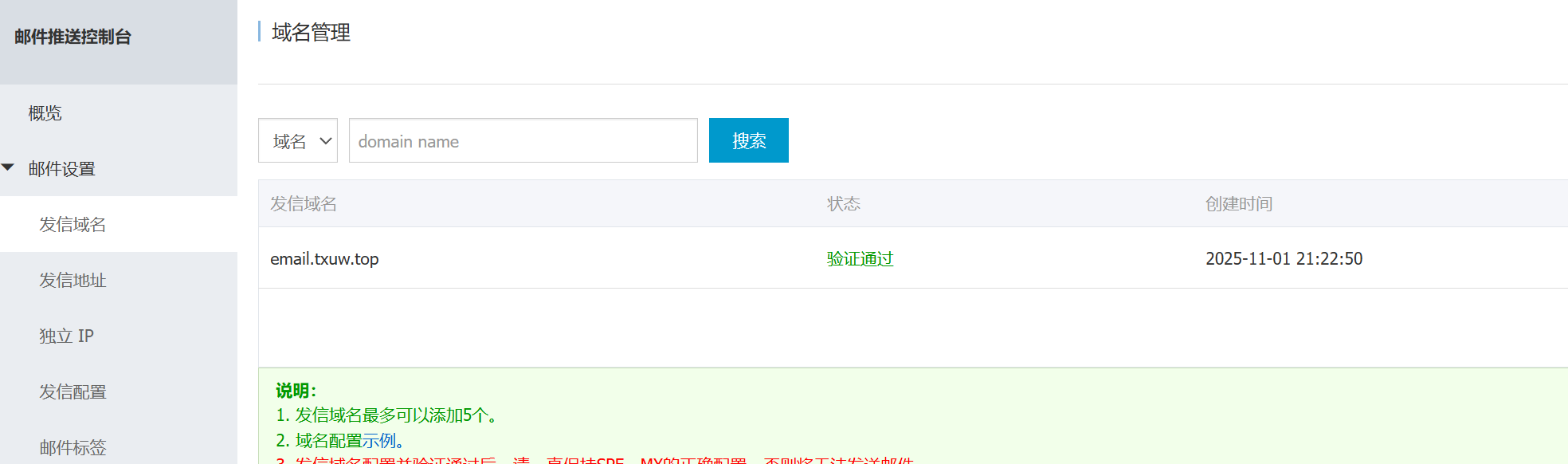
配置发信地址
具体教程如下
这个也就是后续用到的用户名,需要把对应的状态都点亮,不然好像不好使
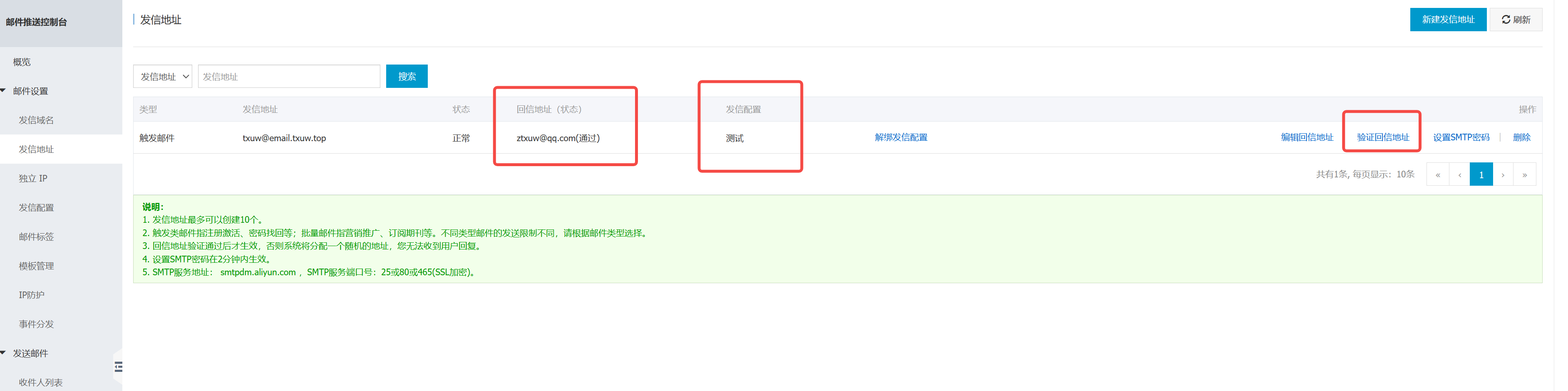
获取对应信息配置到Grafana中
获取对应的推送服务地址
然后在上面grafana安装时的values.yaml中可以看到对应的SMTP相关配置
其中的host就是阿里云的SMTP服务,而user和password就是上面发信地址以及SMTP密码
# 开启SMTP
envFromSecret: "grafana-smtp-credentials"
grafana.ini:
server:
root_url: https://grafana.txuw.top
smtp:
enabled: true
host: "smtpdm.aliyun.com:465"
user: ""
password: ${SMTP_PASSWORD}
from_address: ""
from_name: "Grafana"
skip_verify: false
starttls_policy: "NoStartTLS"配置正常后就可以在Grafana中发信了
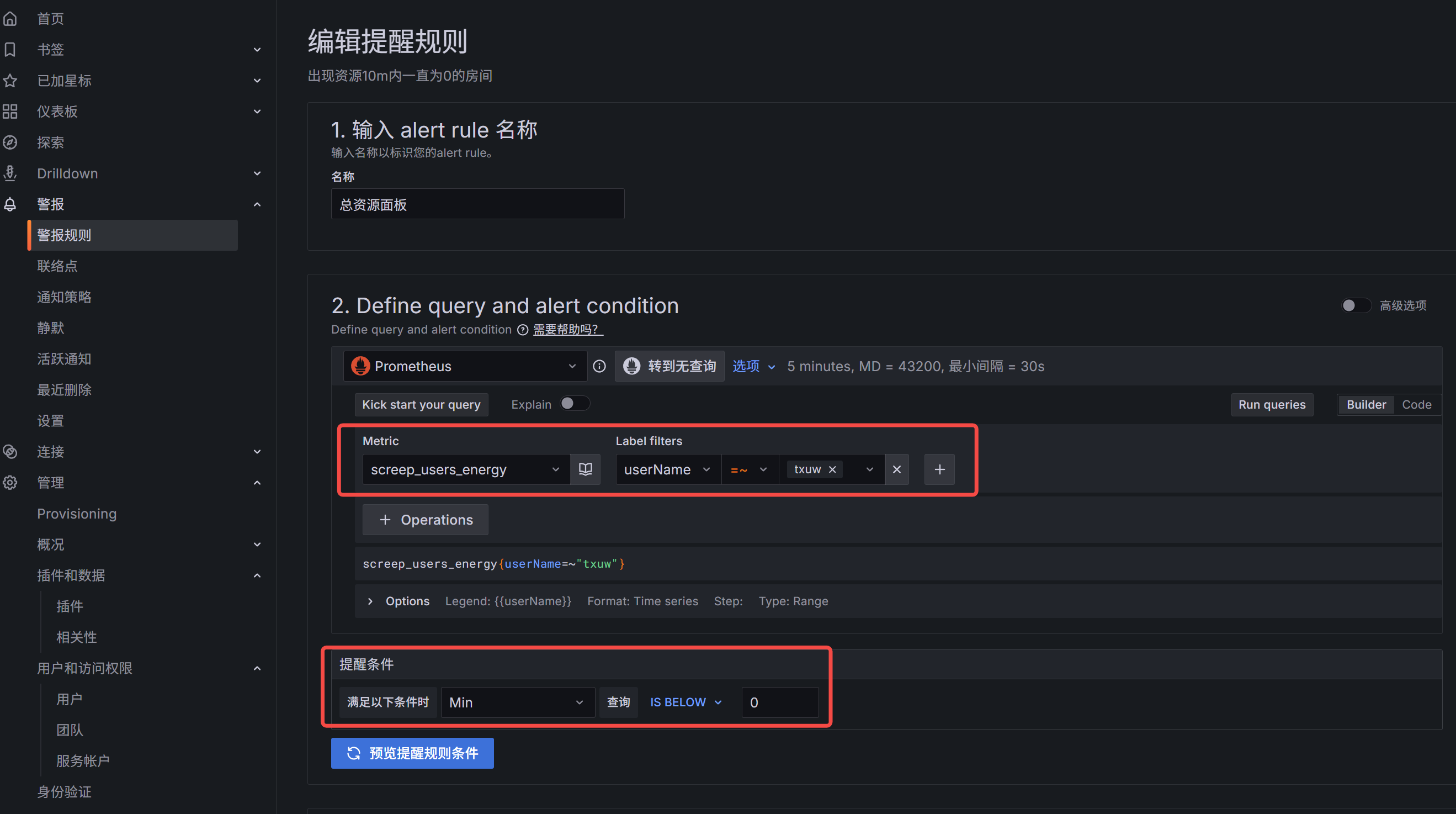
Grafana告警规则配置
需要先在联络点钟配置上每个人的告警邮箱,在配置时可以进行测试发送,防止SMTP配置有问题不知道
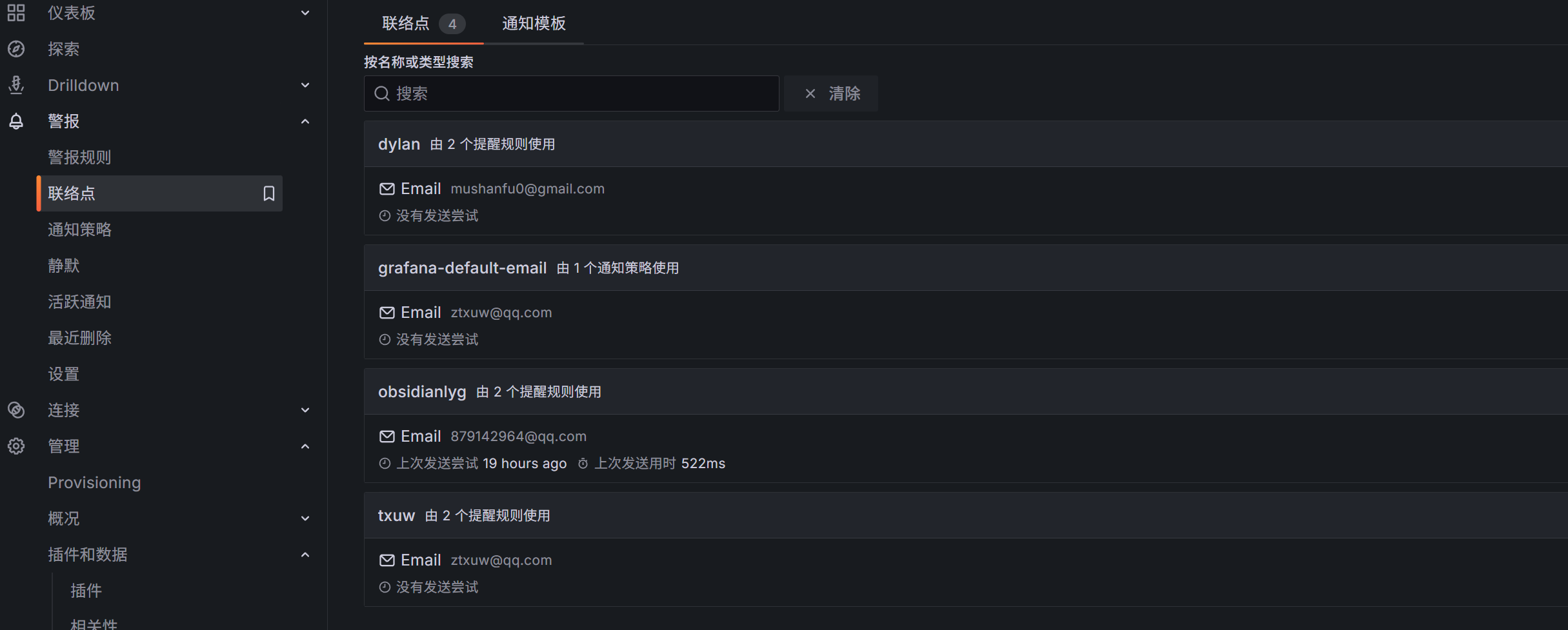
而后就是在报警规则中新建各个规则
比如此处,我需要告警总资源量为0时,进行告警通知,就可以如下配置,因为可能一个人会有多个房间,他会有多个room组,需要取Min,则是存在一个0,就发送告警
展望
计算出房间的整体资源利用率指标[这是个非常复杂的指标,涉及到资源的流向,损耗比等,相当难]
引入战争相关的指标[目前还没有具体的代码实现,也就用不到对应的指标]


